Python Progress Reports: A first glimpse at performance
In the last month, I have ported the reverse geocoding function to the new Python framework. This allows us to have a first look at the question that will be important for the entire project: can Python match the performance of PHP?
The implementation of reverse geocoding is relatively straightforward. Given a coordinate, send a few SQL queries to the database to find the nearest OSM object. There is usually more than one query because there are three different tables to look at: the big placex for all objects OSM, the table with address interpolations from OSM and the table with TIGER data. Depending on the requested zoom level, the algorithm also looks up addresses and POIs first before resorting to returning larger areas like places and boundaries.
Still, reverse geocoding is a very lightweight task for the database in terms of work-load. Much of the time when serving a request is spent parsing it and then formatting the result. So how does Python fare with that?
Performance measurement setup
All of the following measurements were made on a Hetzner EX52-NVME (6x i7-8700 CPU, 128GB RAM, NVME SSD). To make sure that results are comparable, PHP and Python frontends are set up in a similar fashion:
- The PHP-frontend is served by php-fpm with nginx at the front.
- Python is tested with three different web frameworks:
starlette,
sanic and falcon
- starlette and falcon are served with uvicorn fronted by nginx.
- sanic uses its own built-in webserver, also fronted by nginx.
Requests are sent from another machine in the same data center. Each tests sends 1 million queries, which were sampled from the production servers.
Single-query performance
Lets first compare how long a single query takes on average by sending queries sequentially. Here are the average execution times for PHP and Python implementations:
| Implementation | avg. query runtime |
|---|---|
| PHP | 6.3 ms |
| Python (Falcon) | 13.7 ms |
| Python (Sanic) | 13.8 ms |
| Python (Starlette) | 13.9 ms |
It was to be expected that the Python implementation does fare worse. For one thing, Python is known to be slower than PHP. But more importantly, we have switched out SQL query building through string concatenation with a proper SQL-building framework. This is bound to be slower. And this is indeed where most of the time goes. Where the PHP implementation spends about 2/3 of the time in the database, the Python implementation needs 2/3 for itself.
Comparing the different Python frameworks, there is not much difference between them. Falcon is slightly faster than the others but it won’t make much of a difference in practise.
Given that it has no significant performance advantage, I will drop support for sanic in the near feature. The framework tries to be too clever for my taste and does things magically behind the programmer’s back. The result are cryptic errors that are hard to debug and fix. Falcon and Starlette are much easier to handle.
Performance under High Load
Next we want to look at the question how well the different implementations can parallelize higher workload. Lets start with distributing the work load over multiple CPUs. For this test, the server-side gets N worker processes to distribute incomming requests to, while the client side sends a maximum of N requests in parallel. The following table shows the average request execution time for 1 worker, 6 workers (the number of physical CPUs on the test server) and 12 workers (the number of virtual CPUs):
| Number of workers | 1 | 6 | 12 |
|---|---|---|---|
| PHP | 6.3 ms | 7.6 ms | 8.9 ms |
| Python (Falcon) | 13.7 ms | 18.9 ms | 26.8 ms |
While PHP manages to distribute the load almost perfectly over the available CPUs, Python already shows a significant performance degradation when trying to distribute load over the 6 physical CPUs. Where exactly this performance loss comes from is yet unclear to me but it is likely that Python’s larger memory footprint does not play well with the CPU caches. Looking at the distribution of execution times, it is clear that all queries take proportionally longer:
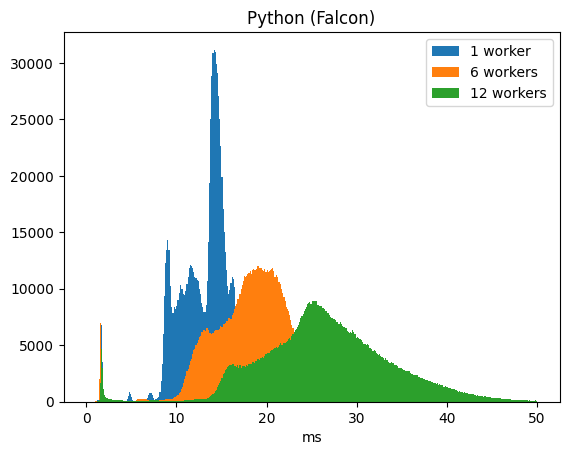
Compare this with the distribution of execution times running with PHP:
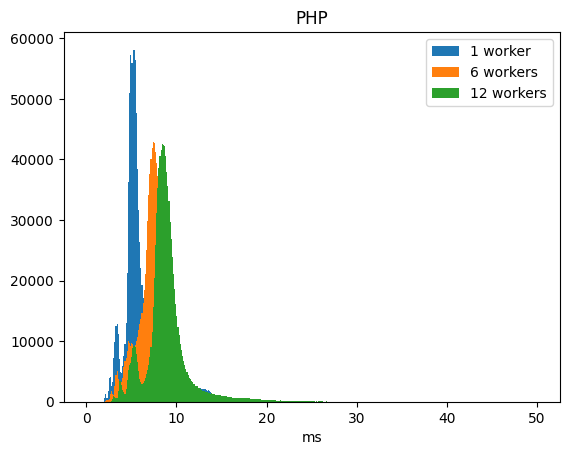
(You will notice multiple ‘humps’ in both diagrams. Depending on the zoom level parameter of the request, Nominatim needs to send a different number of SQL queries to the database. The humps are directly related to the number of queries sent.)
In a final test I tried to see what the maximum throughput on queries is for each implementation. To measure throughput, the client sends 60 requests in parallel and measures how many queries per second can be processed.
The PHP implementation performs optimal with around 15 workers configured and reaches approximately 1500 request/s. The Python/Falcon implementation works optimally with 10 workers and can process around 500 request/s.
Conclusions
The performance measurements above are somewhat of a worst case scenario for the Python implementation. When the database only needs to do reverse lookups, then it can cache all the required indexes in memory, so that the database queries need very little IO and are extremely fast. That makes the slower Python code stand out. A more realistic scenario is that search and reverse queries are mixed. The two types of queries need different kinds of indexes and therefore tend to get into each others way. Thus, reverse queries spend a lot more time waiting for IO. On our production servers, the average execution time of a reverse query is between 15ms and 30ms. The relative overhead of the Python code would be between 30% and 50% and these machines.
The other factor to take into account is that the overhead consists mostly of CPU time. In the performance tests above we really maxed out the available CPUs. This never happens on the production servers. Even the most busy of our servers uses less than 60% of its available CPU. That means that the slower implementation doesn’t necessarily translate into lower throughput but may just be visible in higher CPU usage.
That doesn’t mean that there is no need for improvement. The current implementation makes rather naive use of SQLAlchemy. It can be improved by making better use of SQLAlchemy’s internal query caching. Prepared queries also promise to improve performance. They are currently disabled because they confuse query planning when an SQL query is supposed to rely on partial indexes. And if all that fails, there is also the nuclear option to get rid of SQLAlchemy and go back to hand-written SQL.
However, for now it is still a bit premature to start on performance optimizations. Next up is the implementation of forward geocoding, the search endpoint. Once this is done, the performance test can be repeated with more realistic loads.